개요
오늘은 지난 포스팅에 이어서 실제로 운영체제가 프로세스에게 컴퓨터 자원을 효율적으로 분배하는 전략, 즉 스케줄링 기법에 대해서 알아보도록 하겠습니다.
선점 스케줄링(Preemptive)과 비선점 스케줄링(Nonpreemptive) 기법
운영체제는 CPU, 즉 중앙처리장치라는 비싼 자원을 각 프로세스에게 공정하고 효율적으로 분배하기 위하여 다양한 전략을 채택하고 있습니다.
이 과정에서 어떤 프로세스가 운영체제로부터 중앙처리장치를 할당받은 뒤에 또 다른 프로세스가 중앙처리장치를 요구한다면, 운영체제는 ① 다른 프로세스에게 기다리게 하거나, ② 프로세스의 우선순위를 고려하여 더 높은 우선순위를 가진 프로세스에게 강제로 CPU를 할당해줄수도 있습니다.
이 때, ①의 방식으로 컴퓨터 자원을 관리 하는 기법을 비선점 스케줄링(Nonpreemptive)이라고 하고, ②의 방식으로 컴퓨터 자원을 관리하는 기법을 선점 스케줄링(Preemptive)이라고 합니다.
각각의 스케줄링 기법은 컴퓨터 시스템의 특성과 연관이 깊어서 긴급을 요구하는 프로세스들이 많이 사용되는 실시간 처리 시스템 상에서는 비선점형이 더 효율적일 수 있으며, 절차와 신뢰성 등이 중요한 처리가 많은 컴퓨터 시스템 등에서는 선점형이 더 효율적일 수 있습니다.
지금부터 소개될 다양한 스케줄링 기법들은 현대 사회에 존재하는 다양한 컴퓨터 시스템에 맞는 최적의 스케줄링 기법을 위해 고안된 방법들이라는 것을 인지하시고 살펴보시면 좋을 것 같습니다.
FIFO 스케줄링(First In First Out Scheduling)
FIFO 스케줄링은 그 이름에도 알 수 있듯이 먼저 준비 상태 큐(Ready Queue)에 있던 프로세스에게 먼저 컴퓨터 자원을 분배하는 스케줄링 기법입니다.
가장 원리를 이해하기도 쉬우며 직관적인 비선점 스케줄링(Nonpreemptive) 기법 중 하나입니다.
하지만, FIFO의 경우 겉으로 보기에는 공정해 보일 수 있지만, 작업에 걸리는 시간이 짧은 프로세스가 작업 시간이 긴 프로세스보다 후순위에 위치해 있다면 오랫동안 프로세스를 기다리게 할 수 있습니다.
입력된 순서대로 출력이 되는 형식이다보니 여러 스케줄링 기법 중 그 결과를 예측하기 쉬운 스케줄링 기법 중 하나 입니다.

FIFO에서는 평균 반환 시간이 일반적으로 최소치가 아닌 상당히 큰 폭으로 변화할 수 있다는 특징이 있습니다. 그 이유는 스케줄링 알고리즘의 로직(logic)에서도 유추할 수 있듯이 수행될 프로세스의 ‘순서’에 대해서는 예측하기 쉽지만, 운영체제에 의해 각 프로세스들이 ‘평균적’으로 얼마의 시간이 걸릴지는 예측하기 어렵기 때문입니다.
그리고 FIFO 스케줄링의 방식으로 인하여 여러 프로세스가 작업시간이 긴 하나의 프로세스의 컴퓨터 자원 반납만을 기다리고 있는 현상을 야기시킬 수 있는데, 이러한 현상을 호위효과(Convoy Effect)라고 부르며, 이 때 CPU 사용률과 외부 장치 사용률은 현저히 나빠지게 됩니다.
소스코드
// First In First Out
public class FIFO extends Scheduler implements Nonpreemptive {
public FIFO(){
this.time = 0;
this.taskLength = 0;
this.taskList = new LinkedList<Task>();
}
@Override
public void addTask(Task task) {
this.taskList.add(task);
}
@Override
public void run() {
super.run();
while(!taskList.isEmpty()){
Task mTask = taskList.poll();
this.time = runTask(this.time, mTask);
endedTaskList .offer(mTask); // 종료열에 추가
}
}
}
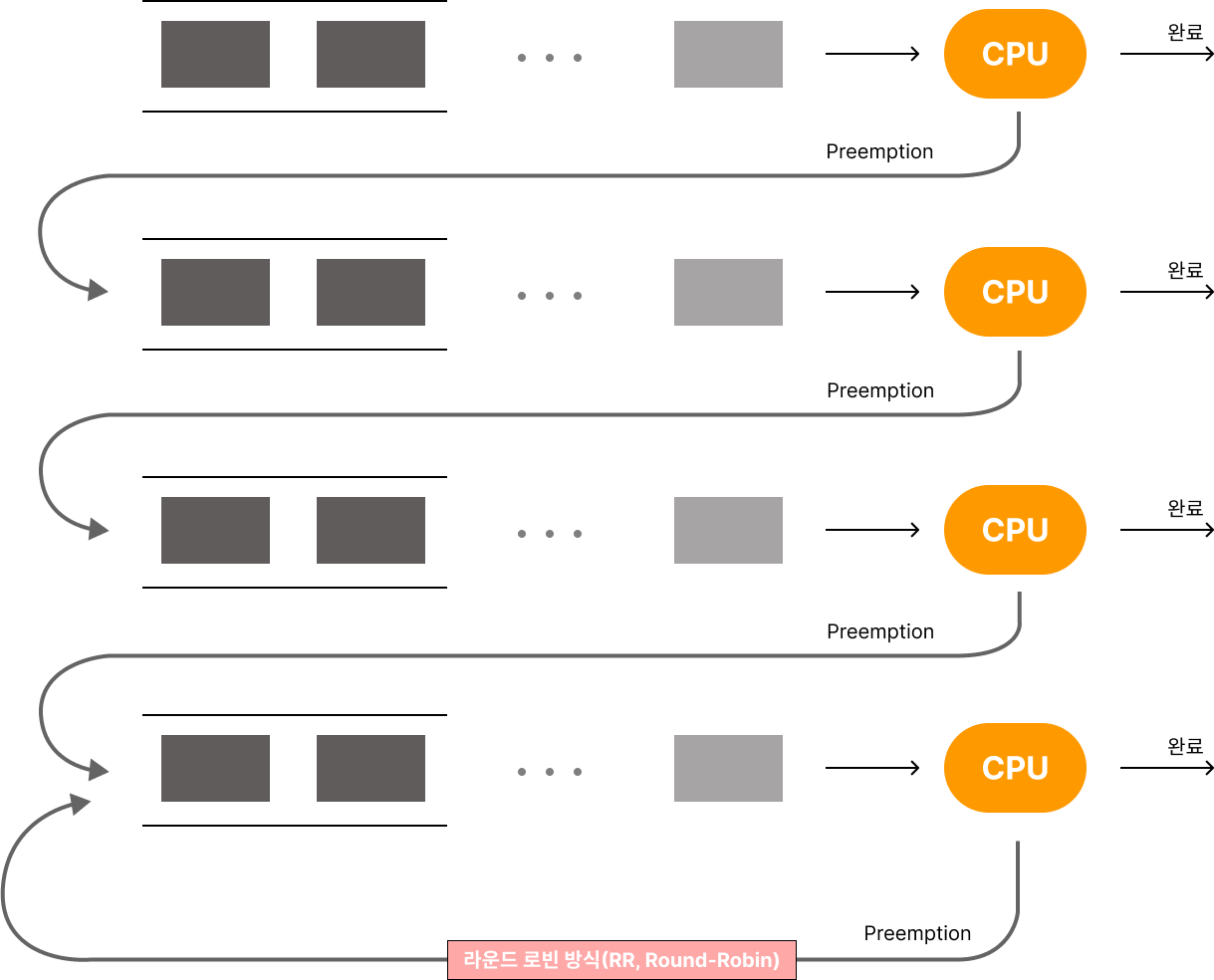
Round-Robin(RR) 스케줄링
Round-Robin(이하 RR)은 FIFO의 단점을 개선하기 위해 고안된 스케줄링 기법입니다.
FIFO와 전체적인 스케줄링 원리는 유사하나, RR에서는 타임 슬라이스(Time Slice) 혹은 시간 할당량이라고 부르는 일종의 ‘타이머(Timer)’를 각 프로세스 별로 함께 분배하게 됩니다.
따라서, 각 프로세스는 준비상태 큐(Ready Queue)에 들어온 순서대로 차례로 컴퓨터 자원을 할당받게 되지만, 작업시간이 긴 프로세스의 경우 주어진 시간을 초과하여 컴퓨터 자원을 사용하게 되면 운영체제로 다시 컴퓨터 자원을 반납 하게 되고, 자기 자신은 다시 준비상태 큐의 가장 마지막 위치로 이동하게 됩니다.
이 방식은 타임 슬라이스라는 장치로 인해서 각 프로세스들이 최대 얼만큼 컴퓨터 자원을 사용할 수 있는지 규격화할 수 있고, 따라서 전체적으로 적당한 응답 속도(Response Time)을 보장할 수 있기 때문에 시분할 시스템에 효과적인 스케줄링 방식입니다.
다만, 작업시간이 긴 프로세스가 타임 슬라이스에 정해진 시간보다 오래 컴퓨터 자원을 사용하여 자신이 사용중이던 자원을 반납하는 과정을 ‘Preemption’이라고 부르는데,
RR 스케줄링 기법에서는 Preemption으로 인해 발생하는 오버헤드(Overhead)로 인해 스케줄링 기법의 성능이 저하될 수 있으므로, 효과적인 *문맥 교환(Context Switching) 기법을 사용하여 오버헤드로 인한 비용을 감소시킬 수 있습니다.
RR은 프로세스가 처음 정의된 규정 시간량보다 더 많은 시간을 사용할 때, 스케줄러는 프로세스가 컴퓨터 자원을 사용하는 것을 중단시키고 다른 프로세스에게 자원을 넘겨줄 수 있으므로 선점 스케줄링(Preemptive) 기법 입니다.
문맥 교환(Context Switching) : 프로세스에 정보를 담고 있는 PCB의 레지스터 영역에 기록된 정보(=PSWR)의 변화가 발생되어 결과적으로 시스템 레지스터에 적재되는 과정, 문맥 교환은 기억 장치의 속도, 레지스터의 개수, 특수한 명령어 등에 의해 편차가 크게 발생할 수 있지만 보통의 경우 10 ~ 100 msec 정도가 소요됨.
소스코드
public class RoundRobin extends PreemScheduler implements Preemptive {
public RoundRobin(int timeSlice) {
super(timeSlice);
this.taskList = new LinkedList<Task>();
}
@Override
public void addTask(Task task) {
this.taskList.add(task);
}
@Override
public void run() {
super.run();
this.time = 0;
this.preemptionCnt = 0;
while(!this.taskList.isEmpty()){
Task pTask = taskList.peek();
if(this.time >= pTask.getArrivalTime()){
Task mTask = taskList.poll();
System.out.println("polled task : " + mTask);
int gap = mTask.getCpuTime() - (this.timeSlice);
this.time += timeSlice;
if(gap > 0){
mTask.setCpuTime(gap);
System.out.printf("[%d] Preemtion!! >> %s is add to back..\n", this.time, mTask.getName());
System.out.println("task status : " + mTask+"\n");
this.taskList.offer(mTask);
this.preemptionCnt++;
continue;
}else if(gap < 0) {
this.time += mTask.getCpuTime();
}
mTask.setEndTime(this.time);
System.out.printf(" [%d] %s is End... %s \n",
this.time, mTask.getName(), mTask
);
endedTaskList.offer(mTask);
}else {
this.time = pTask.getArrivalTime();
}
}
}
}
SJF(Shortest-Job-First) 스케줄링
어떤 프로세스의 작업이 끝나기까지의 실행시간 얼마나 걸리는지 ‘추정치’를 기준으로 하여 가장 빨리 끝나는 작업부터 먼저 시키는 비선점 스케줄링(Nonpreemptive)기법의 하나입니다.
‘추정치’라는 일종의 통계치를 기반으로 스케줄링 하기 때문에 평균 대기시간이 작지만, 대기 시간의 분산은 클 수 있으며 따라서 예측이 오히려 어려워질 수 있습니다.
SJF기법에서는 작업들이 시스템이, 통과하는데 걸리는 평균 대기시간을 최소화시킬 수 있다는 장점이 있습니다.
하지만, 이러한 장점이 실제로 가능해지려면 프로그램의 작업 시간이 ‘예측’가능 해야합니다. 만약 시중에 오랜시간 전에 배포된 프로그램 A가 있고, 이제 막 개발되어 그 성능이나 작업 시간이 얼마정도 걸리는지 알기 어려운 프로그램 B가 있다고 가정하겠습니다.
이 경우 프로그램 A는 SJF 스케줄링 기법에서는 충분히 작업 시간이 예측 가능하므로 적절한 우선순위대로 컴퓨터 자원을 할당받을 수 있을 것입니다. 하지만 프로그램 B의 경우에도 물론 추정치를 만들어낼 수 있겠지만, 그 값이 실제로 동일한지 충분한 ‘검증’이 이루어지지 못했으므로 경우에 따라서는 너무 짧게 평가되거나 길게 평가되어 적절한 우선순위로 컴퓨터 자원을 할당받지 못하게 될 수 있습니다.
따라서, SJF 기법에서는 이러한 근본적인 문제를 해결하기 위해 다음의 세 가지 전략을 채택할 수 있습니다.
- 프로세스의 작업이 추정된 시간보다 오랫동안 실행되면 작업을 중지하고 다른 프로세스에도 이 사실을 알리는 방법
- 프로세스의 작업에 필요로하는 추정 시간보다 약간 더 여유를 줘서 실행시킨 후 그 한계선 마저 넘어버리면 실행을 중지시키고 추후 다시 계속해서 실행될 수 있도록 하는 방법
- 프로세스가 제공한 추정치 이상으로 컴퓨터 자원을 사용하면 일종이 ‘비용’을 부과하여 시간이 지날수록 우선순위가 점차 떨어져서 결과적으로 프리미엄을 부과하는 방법
SJF기법은 주어진 작업들에 대하여 평균 대기시간이 가장 짧다는 이점이 있습니다.
그 이유는 스케줄링 기법의 원리 자체로부터 알 수 있는데, 짧은 작업이 앞으로 이동하기 때문에 전체적으로 프로세스들이 자원 할당을 대기하는 시간을 줄일 수 있기 때문입니다.
아래의 그림처럼 SJF 기법 상에서는 대기 시간이 짧을 것으로 ‘추정’되는 프로세스가 준비 상태 큐(Ready Queue)에서 앞에 위치하도록 조정됩니다.

하지만, SJF는 준비상태 큐에서 프로세스의 우선순위를 정하는데에 ‘추정치’를 사용하기 때문에 CPU가 얼마나 필요로 할지 요구 시간을 알기 어렵다는 단점이 있습니다.
또한, 기본적으로 비선점 스케줄링(Nonpreemptive)의 형태를 띄고 있기 때문에 빠른 응답시간이 필요로하는 시분할 시스템 상에서는 부적합한 스케줄링 기법입니다.
SJF는 이러한 특성 때문에, 프로세스가 수행하는 ‘작업(Job)’에서 스케줄링을 해야할 때 많이 사용 되고 있습니다.
소스코드
// Shortest-Job-First
public class SJF extends Scheduler implements Nonpreemptive {
public SJF(){
this.time = 0;
this.taskLength = 0;
this.taskList = new PriorityQueue<Task>(new Comparator<Task>() {
@Override
public int compare(Task o1, Task o2) {
return o1.getCpuTime() - o2.getCpuTime();
}
});
}
@Override
public void addTask(Task task) {
this.taskList.offer(task);
}
@Override
public void run() {
super.run();
while(!taskList.isEmpty()){
Task mTask = taskList.poll();
this.time = runTask(this.time, mTask);
mTask.setEndTime(this.time); // 종료시간 기록
endedTaskList .offer(mTask); // 종료열에 추가
}
}
}
SRT(Shortest-Remaining-Time) 스케줄링 기법
SRT 기법은 SJF 기법의 아이디어를 선점 스케줄링(Preemptive)으로 변형한 스케줄링 기법입니다.
SRT에서는 각 프로세스의 ‘실행 시간’이라는 값을 기준으로 하여 준비상태 큐(Ready Queue)에 있는 프로세스 중 가장 적은 실행시간을 가진 프로세스에게 자원을 할당해주는 스케줄링 기법입니다.
SJF에서는 ‘작업 시간’에 대한 추정치로 프로세스의 스케줄을 관리하나, 기본적으로는 비선점 스케줄링(Nonpreemptive)이기 때문에 프로세스가 작업을 수행중이라면 그 작업이 끝날 때까지 계속해서 프로세스가 실행됩니다.
하지만, SRT에서는 실행중인 프로세스라고 하더라도 더 짧은 실행시간을 가진 프로세스가 있다면 그 프로세스에게 자원을 할당해주기 때문에 빠른 응답 속도를 필요로하는 시분할 시스템에 적합한 스케줄링 방식입니다.
SRT 기법은 SJF처럼 프로세스의 ‘실행 시간’을 기준으로 스케줄을 관리하고 있지만, 선점형으로 프로세스에게 분배할 자원을 관리하기 때문에 평균 대기시간은 오히려 더 길어진다는 특징을 가집니다.
SRT에서는 SJF와 달리 문맥 교환(Context Switching)에도 분명히 비용이 발생하므로 이 부분도 고려하여 프로세스의 스케줄을 관리해야 합니다. 경우에 따라서는 문맥 교환에 소요되는 비용이 오히려 프로세스를 교체하는 것보다 많이 필요로 하는 경우도 발생할 수 있기 때문에, SRT에서는 이러한 모든 비용을 다 고려하여 임계치(threshold value)를 설정하여 이 값을 기준으로 보다 효율적으로 스케줄을 관리할 수 있습니다.
소스코드
// Shortest-Remaining-Time
public class SRT extends PreemScheduler implements Preemptive {
private Queue<Task> realTimeList;
public SRT(int timeSlice, int threshold){
super(timeSlice, threshold);
this.realTimeList = new PriorityQueue<Task>((o1, o2)->{
return o1.getArrivalTime() - o2.getArrivalTime();
});
this.taskList = new PriorityQueue<Task>(
// 반환 값이 양수일 때: 첫 번째 아이템의 우선순위가 높음.
(o1, o2)->{
int o1Value = 0;
int o2Value = threshold;
if(o1.getCpuTime() == o2.getCpuTime()){
o1Value += o1.getArrivalTime();
o2Value += o2.getArrivalTime();
}else {
o1Value += o1.getCpuTime();
o2Value += o2.getCpuTime();
}
return o1Value - o2Value;
});
}
public SRT(int timeSlice, int threshold, int overhead){
super(timeSlice, threshold, overhead);
this.realTimeList = new PriorityQueue<Task>((o1, o2)->{
return o1.getArrivalTime() - o2.getArrivalTime();
});
this.taskList = new PriorityQueue<Task>(
// 반환 값이 양수일 때: 첫 번째 아이템의 우선순위가 높음.
(o1, o2)->{
int o1Value = 0;
int o2Value = threshold;
if(o1.getCpuTime() == o2.getCpuTime()){
o1Value += o1.getArrivalTime();
o2Value += o2.getArrivalTime();
}else {
o1Value += o1.getCpuTime();
o2Value += o2.getCpuTime();
}
return o1Value - o2Value;
});
}
@Override
public void setThreshold(int threshold){
this.threshold = threshold;
}
@Override
public void addTask(Task task) {
this.realTimeList.offer(task);
}
@Override
public void run() {
super.run();
this.time = 0;
this.taskLength = this.realTimeList.size();
this.preemptionCnt = 0;
this.totalCpuTime = this.realTimeList.stream().mapToInt(Task::getCpuTime).sum();
boolean endFlag = true;
String currentName = "";
do{
if(!this.realTimeList.isEmpty()){
Task pTask = this.realTimeList.peek();
// System.out.println("pTask : "+ pTask);
if(this.time>=pTask.getArrivalTime()){
this.taskList.offer(this.realTimeList.poll());
}
}
if(!this.taskList.isEmpty()){
Task mTask = this.taskList.poll();
if(!currentName.isEmpty()
&& !currentName.equals(mTask.getName())){ // preemption condition
System.out.println(
"[Preemption] process is changed "
+currentName + " to "+mTask.getName()
);
this.preemptionCnt++;
}
currentName = mTask.getName(); // name 갱신
int mCpuTime = mTask.getCpuTime();
if(mCpuTime < 2){
// System.out.println("end Task !!!! ... "+ mTask);
mTask.setCpuTime(0);
mTask.setEndTime(this.time+1);
this.endedTaskList.offer(mTask);
}else {
mTask.setCpuTime(mCpuTime-1);
// System.out.println("Task is running..."+ mTask);
taskList.offer(mTask);
}
}
if(this.taskList.isEmpty()
&& this.realTimeList.isEmpty()){
endFlag = false;
}
time++;
}while(endFlag);
}
}
HRN(Highest Response-Ratio Next) 스케줄링
HRN 기법은 Brinch Hansen에 의해 연구된 스케줄링 기법입니다.
HRN 기법은 SJF 기법의 약점 중 하나인, 긴 작업 시간을 가지는 프로세스와 짧은 작업 시간을 가지는 프로세스의 불평등을 어느정도 보완할 수 있도록 개선했습니다.
HRN 기법은 비선점 스케줄링(Nonpreemptive) 기법의 하나이며, HRN에서 작업의 우선순위는 서비스를 받은 시간, 서비스를 기다린 시간을 아래의 수식으로 계산하여 우선순위를 산정합니다.

이 수식에 따라 우선순위가 계산된 프로세스의 경우 서비스를 받을 시간이 분모에 있으므로 짧은 작업 시간을 가진 프로세스의 우선순위를 높일 수 있습니다.
또한, 대기한 시간이 분자에 있기 때문에 오래 기다린 프로세스의 경우에도 우선순위를 높여줄 수 있습니다.
소스코드
// Highest Response-Ratio Next
public class HRN extends Scheduler implements Nonpreemptive{
public HRN(){
super();
this.taskList = new PriorityQueue<Task>((o1, o2)->{
int o1CpuTime = o1.getCpuTime();
int o2CpuTime = o2.getCpuTime();
float o1Ratio = (
((float) o1CpuTime + (float) o1.getCurrentWaitTime())
/ (float) o1CpuTime
);
float o2Ratio = (
((float) o2CpuTime + (float) o2.getCurrentWaitTime())
/ (float) o2CpuTime
);
int result = Math.round(o2Ratio - o1Ratio);
return result;
});
}
@Override
public void addTask(Task task) {
this.taskList.offer(task);
}
@Override
public void run() {
super.run();
while(!taskList.isEmpty()){
Task mTask = taskList.poll();
this.time = runTask(this.time, mTask);
mTask.setEndTime(this.time); // 종료시간 기록
endedTaskList .offer(mTask); // 종료열에 추가
Queue<Task> tempList = new LinkedList<Task>();
while(!taskList.isEmpty()){
Task nTask = taskList.poll();
nTask.setCurrentWaitTime(this.time-nTask.getArrivalTime());
tempList.offer(nTask);
}
while(!tempList.isEmpty()){
this.taskList.offer(tempList.poll());
}
}
}
}다단계 피드백 큐(Multi-Level Feedback Queue)
SJF 기법에서 프로세스를 관리할 때, 어떤 프로세스가 얼마나 컴퓨터 자원을 사용할지 ‘작업 시간’을 알 수 있었다면 합리적이고 효율적으로 프로세스 스케줄을 관리할 수 있을 것입니다.
하지만 이러한 ‘작업 시간’은 실제로 프로세스에 자원을 할당해보고 그에 걸린 시간을 측정하며 ‘검증’을 해야지 비로소 그 추정치를 정확히 예측할 수 있기 때문에 기준 값을 설정하는 데에 어려움이 있습니다.
다단계 피드백 큐는 이러한 ‘작업 시간’의 애매함을 해소하고, 다음의 세가지 목적을 달성하기 위하여 고안되었습니다.
- 짧은 작업에 우선권을 주어야 한다.
- 입출력 장치를 효과적으로 활용하기 위해 입출력 위주의 작업들에게 우선권을 부여한다.
- 가능한 빨리 작업의 성격을 파악하여 그 성격에 맞는 스케줄링을 제공해야 한다.
다단계 피드백 큐에서는 큐잉 네트워크(한 개 이상의 대기 큐(Ready Queue)들을 서로 연결하여 구성한 큐)의 망으로 프로세스가 들어올 때에는 중앙처리장치를 차지할 때까지 큐 내부에서 FIFO의 형태로 이동시킵니다.
작업이 끝나거나 입출력이 나 다른 사건(event)으로 인해 중앙처리 장치를 양도하기 되는 경우 그 작업은 큐잉 네트워크를 떠나게 합니다.
만약 프로세스가 중앙처리장치를 자발적으로 양도하기 전에 시간의 할당량이 종료되면 그 프로세스는 다음번에는 낮은 수준(level)의 큐로 배치되게 됩니다.
다단계 피드백 큐에서는 큐잉 네트워크를 구성하는 ‘큐’의 우선순위 또한 스케줄링에 반영되므로 해당 프로세스는 다음번에 더 낮은 우선순위로 컴퓨터 자원을 할당받게 됩니다.
만약 프로세스가 매번 주어진 할당량 이상으로 컴퓨터 자원을 사용한 경우에는 궁극적으로는 가장 낮은 우선순위에 배치되는데, 이런 상황에서도 주어진 시간을 초과한다면 해당 프로세스는 프로세스가 완성될 때까지 라운드 로빈(RR, Round-Robin)의 방식으로 컴퓨터 자원을 할당받게 됩니다.
다단계 피드백 큐에서는 이처럼 더 낮은 단계의 큐로 이동할 경우 더 많은 시간 할당량을 부여하는데, 프로세스가 큐잉 네트워크 내에 오래 머물러 있을수록 중앙처리장치를 더 오랜시간 할당받을 수 있습니다.
다단계 피드백 큐 기법에서는 이미 실행중인 프로세스라도 그보다 높은 수준(level)에 위치한 프로세스에 의해 preemption될 수 있다는 특징이 있습니다.
다단계 피드백 큐에서 입출력 위주의 작업들에게 우선권을 부여할 수 있는 이유는, 큐잉 네트워크로 인해 입출력 위주의 작업들은 당연히 CPU의 사용을 최소화 하므로 상대적으로 항상 높은 수준의 큐잉 네트워크의 큐에 위치하다가 큐잉 네트워크를 떠나기 때문에 결과적으로 입출력 위주 작업들에게 우선권을 부여하는 효과를 줄 수 있습니다.
또한, 낮은 단계의 피드백 큐에 있는 프로세스에게는 CPU 사용하기 까지 오랜 대기시간이 필요할 수 있지만, 한번 자원을 할당 받으면 더 오랜 시간 자원을 사용하게 할 수 있으므로 더 합리적이고 효율적으로 컴퓨터 자원을 활용할 수 있게 됩니다.
따라서, 다단계 피드백 큐에서는 다음과 같은 다섯가지 요소로 구성됩니다.
- 큐(Queue)의 수
- 각 큐에 대한 스케줄링 알고리즘
- 작업을 보다 높은 우선순위로 격상시키는 시기의 결정 방법
- 작업을 보다 낮은 우선순위로 격하시키는 시기의 결정 방법
- 프로세스들을 어느 큐에 위치시킬 것인지 결정하는 방법
다단계 피드백 큐 스케줄링은 기존의 스케줄링 기법에서 해결하기 어려웠던 많은 문제 상황들을 해결하게 되었고,
현재 CPU 스케줄링 알고리즘 중에서 가장 일반적인 것이 되었습니다.
이에 따른 다단계 피드백 큐 기법의 특징에 정리하자면 아래와 같이 정리할 수 있습니다.
- 프로세스의 근래의 행동이 미래 행동에 대한 좋은 척도가 된다는 직관을 반영한다.
- 높은 우선순위를 가진 짧은 프로세스나 입출력 위주의 프로세스가 서로 섞이지 아니한다.
- 프로세스의 행동양식이 갑자기 바뀌더라도 신속히 적응하여 대응한다.
- 프로세스의 ‘실행시간’이라는 측정하기 어려운 수치를 효율적으로 평가하고 지능적으로 기록하여 컴퓨터 시스템으로 하여금 다음번 스케줄링에서 더 나은 반응을 제공한다.
- 적응형(adaptive) 기법이므로 오버헤드가 존재하나, 이 비용을 투자하여 더 나은 시스템 성능을 제공할 수 있도록 설계 되었으므로 충분한 투자 가치를 보장한다.
소스코드
// MultiLevelFeedbackQueue
public class MLFQ
extends Scheduler implements Nonpreemptive {
/**
* About Preemption..!
* MLFQ는 NonPreemptive지만,
* 큐잉 네트워트 간에는 preemption이 발생하므로 아래와 같은 비용이 고려되야함.
*/
private int overhead; // 문맥 교환 오버헤드
private int preemptionCost; // preemption 비용
private int preemptionCnt; // preemption 횟수
/**
* Queuing network...
*/
private int networkSize;
private Queue<Task>[] queuingNetworks;
private int timeSlice; // 프로세스의 CPU '최대' 사용 할당량을 정하기 위한 타임 슬라이스
public int getNetworkSize() {
return networkSize;
}
public void setNetworkSize(int networkSize) {
this.networkSize = networkSize;
}
@Override
public void addTask(Task task) {
/**
* 주어진 task 마다 최대 cpu 사용 시간(예상)을 비교하여 슬라이스를 최대로 설정해둔다.
* 왜나하면, 기본적으로 MLFQ는 Nonpreemptive한 스케줄링 방식인데,
* 예상보다 오랜 시간 CPU를 사용하는게 아니면, 자주 Preemption을 발생시킬 경우
* Nonpreemptive한 성격을 잃을 수 있기 때문...
*
* 이러한 초기 세팅은 임의로 한 것이므로, 실제 사용되는 MLFQ 스케줄링과는 상이할 수 있음!
*/
this.timeSlice = Math.max(timeSlice, task.getCpuTime());
/**
* 큐잉 네트워크 구분하는 기준은 러프하게,
* 최대 타임 슬라이스를 큐잉 네트워크의 사이즈로 나누어서
* 그에 해당하는 범위로 재분류한다.
* 따라서, 이 메서드를 통해 들어오는 프로세스는 일단, 전체 대기열에 추가해준다.
*/
this.taskList.offer(task);
}
@SuppressWarnings("unchecked")
public MLFQ(int networkSize){
this.taskList = new LinkedList<Task>(); // 모든 프로세스를 우선 담기 위해 사용...
this.networkSize = networkSize; // 큐잉 네트워크의 사이즈를 선언
// 큐잉 네트워크 사이즈만큼 네트워크를 구성한다.
queuingNetworks = new LinkedList[networkSize];
for(int i = 0; i < networkSize ; i ++){
queuingNetworks[i] = new LinkedList<Task>();
}
/**
* network 간 preemption 관리를 위한 변수 init
*/
this.overhead = 1; // 오버헤드는 아주 작은 수치일 것이므로 1로 임의로 산정
this.preemptionCnt = 0;
this.preemptionCost = 0;
}
@Override
public void run() {
this.time = 0;
this.taskLength = this.taskList.size();
reClassificationTask();
for(int i =0, size = queuingNetworks.length; i < size ; i++){
LinkedList<Task> network = (LinkedList<Task>) queuingNetworks[i];
if(i>0){ // 큐잉 네트워크에서는 첫번째 네트워크가 아닌 경우에는 무조건 Preemption이 일어남
System.out.printf("[Preemption] network %d to network %d \n", i-1, i);
this.preemptionCnt++;
}
while(!network.isEmpty()){ // fifo...
Task mTask = network.poll();
mTask.setCurrentWaitTime(this.time);
this.time = runTask(this.time, mTask);
endedTaskList .offer(mTask); // 종료열에 추가
}
}
this.preemptionCost = overhead * this.preemptionCnt;
printPreemptionData(
timeSlice, overhead, preemptionCost, preemptionCnt
);
}
// 전체 작업 목록을 재분류 하기 위한 메서드
private void reClassificationTask(){
int unit = this.timeSlice / this.queuingNetworks.length;
while(!this.taskList.isEmpty()){
Task mTask= taskList.poll();
for(int i = 0, size = queuingNetworks.length; i < size ; i ++){
int limit = ((i+1)*unit);
// 분류 되거나, 끝에 도달했다면
if(mTask.getCpuTime() <= limit || i == size-1){
queuingNetworks[i].offer(mTask); // 현재 분류에 추가
break;
}
}
}
}
private void printPreemptionData(
int timeSlice, int overhead,
int preemptionCost, int preemptionCnt
){
System.out.printf(
"▶▶▶[%s] all process is ended... preemtion count: %d, timeSlice: %d\n"
+ "preemtion cost is %d [overhead : %d]\n\n",
this.getClass().getSimpleName(), preemptionCnt,
timeSlice, preemptionCost, overhead
);
}
@Override
protected float getAvgWaitTime() {
int totalWaitTime = 0;
while(!endedTaskList .isEmpty()){
Task mTask = endedTaskList .poll();
totalWaitTime += mTask.getCurrentWaitTime();
System.out.println("result... " + mTask+", wait Time : "+mTask.getCurrentWaitTime());
}
return (float) (totalWaitTime * 1f / taskLength * 1f);
}
@Override
protected float getAvgResponseTime() {
return 0; // TODO 구현...
}
}
❗ 주의
- 위 소스코드에서는 시간의 흐름에 따른 프로세스 및 큐잉 네트워크의 우선순위를 고려하지 않고 구현되었습니다.
- MLFQ이 비선점 스케줄링(Nonpreemptive) 기법이라는 점을 고려하여, 동작할 수 있도록 단순화된 로직으로 구현되었습니다.
프로세스 스케줄링 기법 구분
| 유형 | 스케줄링 기법 |
| 비선점 스케줄링 (Nonpreemptive) |
FIFO 스케줄링(First In First Out Scheduling) |
| SJF(Shortest-Job-First) | |
| HRN(Highest Response-Ratio Next) | |
| 다단계 피드백 큐(Multi-Level Feedback Queue) | |
| 선점 스케줄링 (Preemptive) |
Round-Robin(RR) |
| SRT(Shortest-Remaining-Time) |
참고자료
김완규, 고정국, 진광윤, 최신형, 하성권, 허덕행 | 핵심 운영 체제론 | 두양사
'CS BASIC > 운영체제(Operation System)' 카테고리의 다른 글
| [운영체제] 기억장치 (記憶裝置, Memory , Computer Data Storage) (1) | 2024.11.16 |
|---|---|
| [운영체제] 디스크 스케줄링 (0) | 2024.04.01 |
| [운영체제] CPU 스케줄링과 평가 기준 (2) | 2024.01.29 |
| [운영체제] 프로세스와 상태 전이 (0) | 2024.01.22 |
| [운영체제] 운영체제 일반 (1) | 2024.01.15 |



