개요
오늘날의 컴퓨터 시스템이 가진 자원, 즉 프로그램이 사용할 수 있는 다양한 하드웨어 장치들은 운영체제에 의하여 적절히 관리되어 집니다.
오늘은 그 중에서도 가장 중요한 자원 중 하나인 CPU(central processing unit)의 스케줄링에 대해서 알아보도록 하겠습니다.
CPU 입출력의 버스트 주기(CPU I/O Burst Cycle)
프로세스의 실행은 CPU의 실행과 입출력의 대기 상태의 반복입니다.
즉, 프로세스는 이 두 가지 상태를 오가며 실행이 되고, 주어진 작업(Job)을 수행하게 됩니다.
프로세서(=CPU)의 실행은 CPU 버스트(Burst)라는 것을 통해서 이루어지며, CPU 자원을 할당받고 주어진 작업을 수행하다가, 사용자로부터 입출력을 받아야 할 때에는 입출력 버스트(I/O Burst)를 통해서 프로세스의 상태를 전이시킬 수 있습니다.
이 과정을 그림으로 나타내면 아래와 같습니다.

CPU 버스트의 소요 시간은 프로세스에 따라, 컴퓨터에 따라 다르지만 <fig 1.1>과 같이 곡선을 그리게 됩니다.

이러한 곡선은 일반적으로 지수형(exponential) 또는 초지수형(hyper-exponential) 형태를 가집니다.
입출력 중심의 작업은 많은 수의 아주 짧은 CPU 버스트가 발생하고,
반면에 CPU 중심의 작업은 적은 수의 아주 긴 CPU 버스트를 가진다는 특징이 있습니다.
이러한 분포는 운영체제가 CPU 스케줄링 알고리즘을 선택하는데 있어서 중요한 기준이 됩니다.
버스트와 프로세스의 상태 전이
프로세스 상태 전이에 대한 자세한 설명은 지난 포스팅을 참고 하시면 좋을 것 같습니다.
[운영체제] 프로세스와 상태 전이
개요 프로세스의 정의는 실행중인 프로그램, 비동기적인 행위 등 여러가지로 정의할 수 있습니다. 그러나 일반적으로 “프로세스”라고 부르는 것은 “실행중인 프로그램”을 의미합니다. 하
1-hee.tistory.com
프로세스란 실행상태에 있는 프로그램을 일컫는 말입니다.
버스트(Burst)과정에서 프로세스의 실행은 CPU 버스트와 입출력 버스트를 혼합하여 반복하는 사이클을 형성하는데, CPU 버스트로 시작되고 CPU 버스트로 종료됩니다.
이 과정에서 프로세스는 생성(new), 활동(active), 대기(wating), 중단(halted) 중 하나의 상태에 놓이게 되는데 이에 따른 프로세스의 상태 전이도를 그림으로 표현하면 아래와 같습니다.

프로세스 제어 블록(Process Control Block)
하나의 프로세스는 프로세스 제어블록(Process Control Block), 또는 작업 제어블록(Task Control Block)이라는 블록(Block, 컴퓨터 시스템안에서 정보를 저장하기 위해 기록한 물리적인 저장소)으로 관리 및 표현됩니다.
프로세스 제어 블록은 약칭으로 PCB라고 줄여서 자주 사용되고 있으며, PCB는 하나의 프로세스에 대하여 아래와 그림과 같이 프로세스의 관리에 필요한 정보를 가집니다.
프로세스 제어 블록(PCB)이 관리하는 정보
| 정보 | 설명 |
| 프로세스의 상태 | - 생성(new), 준비(ready), 실행(running), 유휴(idle), 중단(halted) 등의 상태 표시 |
| 프로그램 계수기 (PC, Program Counter) |
- 프로세스를 수행하기 위한 다음 명령의 주소를 표시한 장소 |
| CPU 레지스터 | - 누산기(Accumulator), 색인 레지스터(Index Register), 범용 레지스터(General Purpose Register), 조건 코드(Condition Code) 등에 관한 정보. - 컴퓨터 구조에 따라 수나 형태(type)이 변화함. - 인터럽트 발생시 PC와 함께 저장되어 다시 수행하는 과정에서 프로세스 복구에 사용. |
| 주기억 장소 관리 정보 | - 기준 레지스터(Base Register), 한계 레지스터(Bound Register), 페이지 표(Page Table)을 포함 |
| 계정 정보 (Accounting Information) |
- CPU 사용 시간, 실제 사용 시간, 한정된 시간, 계정 번호, 작업이나 프로세스 번호 등을 포함 |
| 입출력 상태 정보 (I/O Status Information) |
- 특별한 입출력 요구 프로세스에 할당된 입출력 장치, 개방된(opened) 파일의 목록 |
| CPU 스케줄링 정보 | - 프로세스의 우선 순위, 스케줄링 큐에 대한 포인터, 그외 다른 스케줄 관련 매개 변수 |

PCB는 프로세스마다 다른 여러 정보에 관련한 정보의 저장소 역할만을 수행합니다.
PCB는 모니터 기억 장소에 위치하며 여러 방법으로 관리 되는데,
가장 쉬운 방법 중 하나는 최대 프로세스 수를 선언하고 모든 PCB에 충분한 공간을 미리 할당해주는 것입니다.
일반적으로 PCB의 수는 시간에 따라 변화하기 때문에 동적으로 저장소를 관리하는 것이 좋습니다.

CPU 스케줄링 알고리즘의 성능 기준(Performance criteria for CPU scheduling algorithms)
운영체제가 프로세스에 CPU를 할당하고 회수하는 과정은 적절한 알고리즘을 사용했을 때 최대의 효율을 낼 수 있을 것입니다.
그리고 이러한 효율을 평가하기 위해서는 CPU 스케줄링에 사용되는 알고리즘에 대한 성능의 기준(Performance criteria)을 정하고 이에 따라 평가해야할 것입니다.
CPU 스케줄링 알고리즘의 성능 평가에 사용되는 기준은 아래와 같습니다.
| 성능 평가 기준 | 설명 |
| CPU 사용률 | - CPU가 유휴 상태에 놓이는 것을 최소한으로 하는지 평가하는 척도입니다. - 보통의 컴퓨터에서 CPU의 사용률은 40%(가벼운 부하)에서 90%(아주 무거운 부하) 범위에서 달라집니다. |
| 처리율 (throughput) |
- 단위 시간 당 완료되는 작업의 수를 말합니다. |
| 반환 시간 (Turnaround TIme) |
- 프로세스가 수행해야할 작업(Job)이 시스템에 맡겨져서 주기억장치에 들어가기 전 까지의 시간, 준비상태 큐에 있는 시간, 실행 시간, 입출력 시간 등 모든 작업을 마치고 시스템으로부터 빠져 나올 때까지 소요되는 시간을 말합니다. |
| 대기 시간 (Waiting Time) |
- 프로세스가 준비 상태 큐에서 기다리는 시간입니다. - 때로는, 스케줄링 알고리즘이 입출력이나 작업의 실행에 영향을 주지 못해서, 반환 시간을 고려하지 않고 대기 시간만을 고려하여 평가하기도 합니다. |
| 반응 시간 (Response Time) |
- 대화형 시스템에서 중요한 평가 척도로, 어떤 작업을 의뢰한 시간으로부터 반응이 시작되는 시간 까지의 시간을 평가하는 척도입니다. - 실제 프로세스가 작업을 수행하는 시간은 고려되지 않으며, 출력 장치의 속도에 거의 종속적으로 지배됩니다. |
운영체제는 이러한 성능 평가 기준을 바탕으로 컴퓨터 시스템에서 프로세스가 효율적으로 컴퓨터 자원을 사용할 수 있도록 하는데,
CPU 사용률과 처리율(throughput)을 최대화하고 반환 시간(Turnaround TIme)과 대기 시간(Waiting Time) 그리고 반응 시간(Response Time)은 최소화하는 방향으로 개선하는 것이 좋습니다.
CPU 스케줄링을 개선할 때에는 평균 값 보다는 최대 최소치를 최적화하는 것이 더 바람직합니다.
예컨데, 사용자가 원만한 서비스를 받도록 보장하려면 오히려 최대 반응 시간(Maximum Response Time)을 최소화하여 쾌적한 서비스를 제공할 수 있습니다.
반면에 사용자와의 상호작용이 많은 대화형 시스템에서는 반응 시간의 평균을 최적화하기 보다 반응 시간의 최소와 최대 값의 편차(Variance)를 줄이는 것이 오히려 성능 향상에 도움이 됩니다.
스케줄링 큐(Scheduling Queues)
운영체제는 프로세스가 필요한 다양한 컴퓨터 자원을 특정 기준이나 우선순위를 바탕으로 할당하고 회수하는 작업을 담당합니다.
이 과정에서 필연적으로 컴퓨터 내에서 실행 가능한 프로그램의 수는 다수일 수 밖에 없는데, 따라서 운영체제는 여러 개의 프로세스를 효율적으로 관리하기 위해서 일종의 장바구니와 같은 도구를 사용하는 것이 효율적입니다.
즉, 운영체제가 각 프로세스에 필요한 컴퓨터 자원에 대해 관리할 때에 효율성을 제고할 목적으로 만들어진 관리용 도구가 스케줄링 큐(Scheduling Queues) 입니다.
컴퓨터 시스템에서 관리하는 다양한 자원은 때로는 자원의 특성을 고려하여 더 적합하게 프로세스가 자원을 사용할 수 있도록 스케줄링 큐를 사용할 수 있습니다.
그리고 컴퓨터 자원중 가장 중요하고 또 유명한 자원 중 하나인 CPU도 CPU에 특성에 맞도록 최적화된 스케줄링 큐를 사용할 수 있으며, 이 때 사용되는 스케쥴링 큐를 준비 상태 큐(Ready queue)라고 합니다.
운영체제는 CPU의 사용을 기다리는 다양한 프로세스들을 준비 상태 큐(Ready queue)에 모아둡니다.
준비 상태 큐는 일반적으로 연결 리스트(linked list)의 구조로 되어 있으며 머리(head)부분과 꼬리(tail) 부분은 PCB 목록의 첫 항목과 끝 항목을 가리키고 있습니다. 또한, PCB에는 포인터가 있어서 다음 항목을 지시할 수 있습니다.
준비상태 큐(Ready Queue)는 일반적으로 큐(Queue)에서 사용되는 선입 선출(FIFO, First in First Out)의 구조를 가질 필요는 없습니다.
경우에 따라서는 우선순위 큐(Priority Queue)라던지 트리(Tree), 스택(Stack), 무순서, 연결 리스트(Linked List)로 관리되기도 하는데, 어떤 구조던지 프로세스를 효율적으로 관리하는 데 더 적합하다면 상황에 맞는 자료 구조를 채택하는 것이 합리적일 수 있습니다.

만약 시분할 터미널과 같은 전용 장치를 사용하는 상황이라면 스케줄링 큐에는 한 프로세스 밖에 있을 수 없는데, 장치에 대한 공유가 가능하다면 여러 프로세스가 있을 수 있습니다.

프로세스는 처음에 외부로부터 준비 상태 큐로 들어갑니다.
여기서 프로세스는 CPU에 의해 선택될 때까지 기다리다가 CPU에 의해 실행되면 입출력 큐로 옮겨가 입출력 과정을 기다립니다. 이렇게 입출력과 CPU 작업을 반복하기 위해 각각의 큐(입출력 큐, 준비상태 큐)에서 들어갔다가 나오는 과정(그림. <CPU 스케줄링의 큐잉 도표> )을 반복하며 프로세스는 자신이 해야할 작업을 수행합니다.
스케줄러(Scheduler)란?
운영체제가 어떤 프로세스에게 컴퓨터 자원을 할당할 것인지는 스케줄링 큐(Scheduling Queues)를 통해서 관리할 수 있습니다.
하지만, 실제로 운영체제가 컴퓨터 자원을 프로세스에게 할당하기 위해서는 ① 어떤 프로세스를 관리의 대상으로 삼을 것이고, ② 자원을 할당해 줄 때 어떤 프로세스에게 줄 것인지 두 가지 측면에서 판단을 내려야 합니다.
그리고 이러한 판단을 위해 사용하는 것이 스케줄러이며,
①의 판단에 사용하는 것이 장기 스케줄러(Long-term Scheduler)이고 ②의 판단에 사용하는 것이 단기 스케줄러(Short-term Scheduler) 입니다.
두 스케줄러의 가장 큰 차이점 중 하나는 스케줄러의 작업에 소요되는 시간의 차이입니다.
장기 스케줄러의 경우 사람의 비유하면 장기적인 목표를 설정하는 것과 같기 때문에 상대적으로 긴 시간(보통 분 단위)을 주기로 하여 작업을 수행합니다.
반면, 단기 스케줄러의 경우 단기 목표의 설정과 같이 매우 짧은 시간 단위에 따라 판단을 내리고 작업을 수행하게 됩니다.
특히 단기 스케줄러의 경우 그 속도가 매우 빨라야만 하는데, 그 이유는 오늘날의 CPU의 처리 속도는 매우 빨라서 100만 분의 수 초의 단위로 이루어지기 때문에 스케줄러가 최소한 100만분의 10초의 단위로 실행되어야 프로세서의 성능을 크게 저하시키지 않기 때문입니다.
에컨데, 단기 스케줄러가 어떤 프로세스에게 자원을 할당할지 선택하는 과정이 100만분의 1초를 소요한다고 하더라도, 단순 계산을 해보았을 때 전체 속도의 약 9% 정도를 차지하는 과정이 되는 만큼 단기 스케줄러는 CPU에 준하는 빠른 속도로 작업을 처리해야 합니다.
장기 스케줄러는 작업이 시스템을 나갈 때만 실행되기 때문에 단기 스케줄러에 비하면 실행 간격이 상대적으로 긴 편입니다. 하지만 장기 스케줄러가 작업을 선택하는 것은 매우 신중해야 하는데, 그 이유는 장기 스케줄러의 목적에도 알 수 있듯이 운영체제가 프로세스와 자원을 관리하는 청사진을 그리는 데에 지대한 영향을 주기 때문입니다.
즉, 장기 스케줄러는 실행 시간이 상대적으로 길지만 한 번에 실행하는 작업의 중요도는 전체 스케줄링 작업에 큰 영향을 줄 수 있으므로 신중하게 결정되어야 한다는 특징이 있습니다.
장기 스케줄러가 관리하는 작업은 대부분 입출력 중심(I/O bound) 작업과 CPU 중심 작업(CPU Bound)으로 구분될 수 있는데, 두 작업은 적절히 섞여서 사용될 수록 전체 시스템의 성능이 좋아지기 때문에 장기 스케줄러는 이 두 가지 작업을 적절히 섞어주어야 합니다.
반면, 이러한 장기 스케줄러가 없고 중간 단계 스케줄러(Medium Term Scheduler)가 존재하는 경우도 있습니다. 이와 관련한 가장 대표적인 컴퓨터 시스템이 시분할 시스템이며, 단지 새로운 프로세스를 주기억 장치에 넣어주기만 하면 되기 때문에 장기 스케줄러에 의한 시스템 안정성은 기대할 수 없고 시스템에 의해 제한된 사용 가능한 터미널의 수나 사용자 자체에 의해 전적으로 의존하게 됩니다.

중간 단계 스케줄러는 프로세스가 CPU를 서로 차지하려는 교착 상태에 놓이게 될 때, 프로세스를 기억장소로부터 빼낼 수 있어서 다중 프로그래밍의 정도를 줄일 수 있다는 장점도 있습니다.
이때 이 프로세스는 주기억장치에 들어와서 수행이 중단되었던 곳에서부터 다시 작업을 수행하게 되는데 이러한 기법을 교체(swapping)이라고 하며, 교체 시 들어오고 내보내는 작업은 중간 단계 스케줄러(Medium Term Scheduler)가 수행하게 됩니다.
CPU를 할당받을 프로세스를 관리하기 위하여 준비상태 큐(Ready Queue)가 있었던 것처럼, CPU의 스케줄링을 위한 스케줄러는 분배기(Dispatcher)라는 것을 통해서 궁극적으로는 프로세스에 CPU를 할당하게 합니다.
분배기는 실제로 프로세스의 레지스터를 적재(load)시키고, 사용자 상태(user mode)로 전환시켜주며, 다시 시작할 때 사용자 프로그램이 올바른 위치에 놓일 수 있도록 하는 기능을 포함합니다. 따라서, 이러한 분배기는 빠르면 빠를수록 좋습니다.
스케줄링 단계
스케줄링은 아래의 그림과 같은 세가지 중요한 단계를 고려할 수 있습니다.
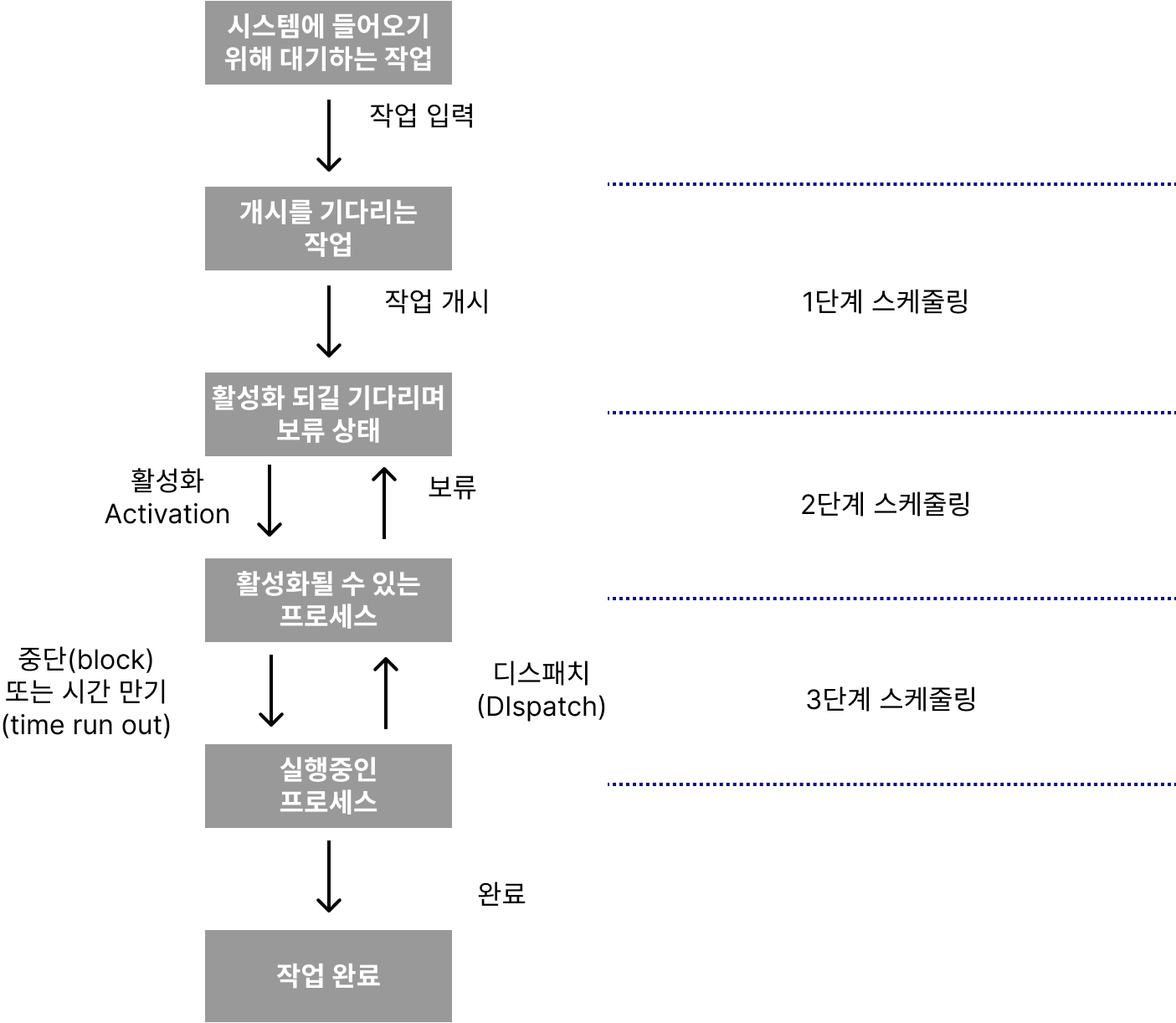
| 스케줄링 단계 | 설명 |
| 1단계 스케줄링 | - 작업 스케줄링(Job Scheduling)이라고 불림(= 승인 스케줄링, Admission Scheduling) - 어느 작업부터 시스템의 자원들이 실제로 사용할 수 있도록 할 것인지 결정 - 프로세스의 그룹을 형성함 |
| 2단계 스케줄링 | 어떤 프로세스부터 중앙처리장치(CPU)를 차지할 수 있는지 결정 프로세슬르 일시 보류시키고 다시 활성화시키는 기법을 사용 단기적으로 시스템에 대한 부하를 조절 가능 1단계 스케줄링에 의한 시스템으로의 작업 승인과 작업들에 대한 CPU 배당 사이의 완충지대 |
| 3단계 스케줄링 | 중앙처리장치(CPU)가 이용가능할 때 어떤 프로세스에게 배당될지를 결정 1초에도 여러번 작동하는 디스패처(Dispatcher)에 의해 이루어짐 항상 주 기억장치에 적재되어 있어야 한다. |
스케줄링의 목적
운영체제가 프로세스에게 자원을 할당하기 위해서는 다음과 같은 목적을 고려하여야 합니다.
- 공정해야 해야 하고, 어느 프로세스도 무한정으로 실행이 연기되어서는 안된다.
- 단위시간당 처리량이 최대화 되어야 한다.
- 대화식 사용자에게는 가능한 빠르게 응답을 주어야 한다.
- 일정한 작업은 같은 시간에 거의 같은 비용으로 실행되어야 하며, 이를 통하여 예측이 가능해야 한다.
- *오버헤드(overhead)를 최소화시켜야 한다.
- 자원의 사용에 있어서 균형을 이루어서 시스템 내의 자원들을 가능한 쉬지 않도록 유지해주어야 한다.
- 응답 시간과 자원의 활용간에 균형을 이루어 자원들을 필요로할 때마다 즉각적으로 이용할 수 있도록 충분한 자원을 확보할 수 있게 끔 한다.
- 실행이 무한정 연기가 된 교착상태(DeadLock)과 같은 나쁜 상황을 피하고, 에이징(aging)과 같은 기법을 사용해 하나의 프로세스가 자원을 오래 기다리지 않도록 프로세스의 우선순위를 높여주어 결과적으로 무한적으로 실행이 연기되는 것을 피해야한다.
- 스케줄링 기법을 위해 우선순위가 높은 프로세스를 먼저 실행시키는 우선순위제도를 실행하는 것이 좋다.
- 우선순위가 낮은 프로세스가 주요 자원을 차지하고 있으면, 그 자원은 다른 프로세스에게 중요한 것일 수 있으므로 주여 자원을 차지하고 있는 프로세스가 먼저 사용할 수 있도록 우선권을 주어야 한다.
- 페이지 부재율과 같은 프로그램 실행 시에 바람직한 행동을 프로세스에게 더 좋은 서비스를 제공하여야 한다.
- 시스템에 부하가 일어나더라도 성능 체증은 서서히 일어나도록 처리해야 한다.
*오버 헤드 : 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 · 메모리
스케줄링 기법의 목적
스케줄링의 목적, 즉 합리적이고 효율적인 컴퓨터 자원의 활용을 위해서는 다음과 같은 사항을 고려해야 합니다.
- 입출력 위주의 프로세스여서 프로세스가 중앙처리 장치를 잠시동안만 사용하는가?
- 프로세스가 중앙처리 장치에서 연산만을 계속하는가?
- 프로세스가 배치(batch)형인가 대화형인가?
- 실시간 응답이 필요하는 시스템의 경우 얼마나 긴급한가?
- 프로세스의 우선순위
- 프로세스가 얼마나 자주 페이지 부재를 발생시키는가
- 각 프로세스들이 얼마나 자주 높은 우선순위의 프로세스에 의하여 자원을 빼았겼는가?
- 프로세스가 얼마나 많은 실제 실행시간을 얻었는가?
- 프로세스가 끝나려면 얼마나 더 많은 시간이 필요로 하는가?
참고자료
김완규, 고정국, 진광윤, 최신형, 하성권, 허덕행 | 핵심 운영 체제론 | 두양사
https://ko.wikipedia.org/wiki/%EC%A4%91%EC%95%99_%EC%B2%98%EB%A6%AC_%EC%9E%A5%EC%B9%98
중앙 처리 장치 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. CPU는 여기로 연결됩니다. 다른 뜻에 대해서는 CPU (동음이의) 문서를 참고하십시오. 핀이 없는 LGA의 인텔 i7 8700k 마이크로프로세서 핀이 있는 PGA의 AMD 라이젠 3700
ko.wikipedia.org
https://en.wikipedia.org/wiki/Block_(data_storage)
Block (data storage) - Wikipedia
From Wikipedia, the free encyclopedia Sequence of bits or bytes of a maximum predetermined size This article is about the computer input/output technique. For the process scheduling concept, see Blocking (computing). In computing (specifically data transmi
en.wikipedia.org
https://ko.wikipedia.org/wiki/%EC%98%A4%EB%B2%84%ED%97%A4%EB%93%9C
오버헤드 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 오버헤드(overhead)는 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 · 메모리 등을 말한다. 예를 들어 A라는 처리를 단순하게 실행한다면 10초 걸리는데,
ko.wikipedia.org
'CS BASIC > 운영체제(Operation System)' 카테고리의 다른 글
| [운영체제] 기억장치 (記憶裝置, Memory , Computer Data Storage) (1) | 2024.11.16 |
|---|---|
| [운영체제] 디스크 스케줄링 (0) | 2024.04.01 |
| [운영체제] 선점 스케줄링(Preemptive)과 비선점 스케줄링(Nonpreemptive) 기법 (1) | 2024.02.05 |
| [운영체제] 프로세스와 상태 전이 (0) | 2024.01.22 |
| [운영체제] 운영체제 일반 (1) | 2024.01.15 |



